
Modern programming languages abstract a lot of low-level details of how our code works. Nonetheless, a good understanding of underlying computer science concepts can help you write better code… and pass technical interviews 😉 Let’s talk about what is a CPU cache and why it’s important.

During my computer science degree, I learned about basic building blocks of electronic circuits, and how they can be used to build logic gates. Those logic gates provide a layer of abstraction that allows engineers to reason in terms of logic operations, and not electrical currents and voltages.
Logic gates can be combined to build a computer that provides us with another layer of abstraction. It allows a programmer to think in terms of a set of available CPU instructions and not just logic gates.
Languages like Python allow programmers to think in terms of high level concepts and not just basic operations the CPU supports — that’s yet another layer of abstraction.

In computer science, more than in any other field, we have many layers of abstraction that enable us to solve problems faster, without worrying about the underlying implementation.
But there is no such thing as a perfect abstraction. All abstraction leak at one point or another, and we suddenly have to deal with the underlying complexity.
That’s one of the reasons programming is so fun… and frustrating. Concepts and ideas interweave, sometimes making debugging very challenging — but also very rewarding.
High level question— low level answer
Let’s look at an example — a high level problem. Let’s say you have to decide between using a linked list and an array. The main requirement is that iterating through elements has to be as fast as possible. What do you think — which data structure will be faster?
The time it takes to iterate through all elements is proportional to the number of elements — the bigger the list/array, the longer it will take to visit all elements. Quite intuitive, right?
From a high-level point of view, it should not matter if you chose to use an array or a list. Both data structures should take more or less the same amount of time.
You might be surprised to learn that an array can be significantly faster than a linked list.
But whyyyyyyyyy
To understand why, we have to go down many levels of abstraction — we have to investigate how the hardware you’re using works. First, we need to understand what a CPU cache is.
Modern processors are very fast in comparison to how much time it takes to access main memory. To reduce the time it takes to access RAM, data that is most likely to be needed by the CPU is placed in a memory that’s smaller, faster, and located “closer” to the processor. We call that memory CPU cache.
Imagine working in a grocery store that is getting its supplies from a big warehouse. The warehouse can store a lot of stuff but it takes a while to find and access things kept there.
That’s why every grocery store has a certain supply of all products (those most likely to be purchased by customers) stored on its premises. You can’t store that many things in the store, but they are quickly accessible.
This is exactly how a CPU cache works.

You might be asking: how do we know what data should be stored in cache?
A computer program is basically just a sequence of instructions to be executed by the CPU. Those instructions are often accessed in order, one after another.
The same is true for arrays — we often iterate through them, accessing all elements in order, one after another. If we’re accessing an element with an index 5, it’s also likely we are interested in elements 6 and 7.
That’s why memory addresses that are “close” to a recently accessed address are more likely to be visited again. When accessing some memory, “nearby” segments of memory should be place in cache as well.
Okay, that is interesting. But what does it have to do with our data structures?
Let’s supposed that a CPU needs to access some memory address. First, it will check if it’s available in the cache. If it is, then it can be accessed very quickly.
However, if it’s not currently stored in the cache, we have to fetch it from the main memory. We call that a cache miss. Cache misses slow down the execution of our code because accessing the main memory is relatively slow.
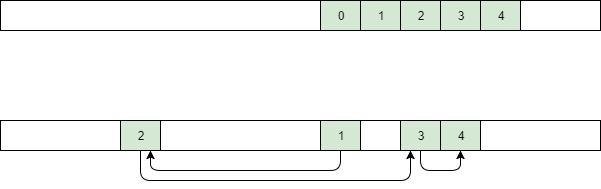
Since all elements in the array are stored as a continuous block of memory, when
reading an element with some index k, following elements (k+1, k+2,
k+3,…) will be cached as well.
This leads to fewer cache misses and results in better performance compared to a linked list, as in a linked list elements might be scattered around the memory.
To answer a seemingly simple question we had to dive really deep. We had to understand what a CPU cache is and how it works.
I think we can all agree — programming never gets boring 😀